
AWS API Gateway is an awesome service to use as an HTTP frontend. You can use it for building serverless applications, for integrating with legacy applications, or for proxying HTTP requests directly to other AWS services.
But understanding the elements of API Gateway can be difficult. If you're like me, your understanding of API Gateway might be like the following:

"Ohh, you know. A user makes a request. It goes to API Gateway. MAGIC HAPPENS. It goes to my Lambda function. MORE MAGIC HAPPENS. And it returns a response! Easy." -- Me, explaining API Gateway before this post.
And while ignorance can be bliss, you're missing out on a lot of API Gateway's power if you don't understand its elements.
After reading this post, you'll understand all the pieces in the following diagram:

Which will make you feel like:

In this post, you'll learn the different steps in an API Gateway request. For each step, we'll see what you should be doing in that step and how it fits in the overall picture.
This post is pretty long, so you may not want to read it all in one sitting. Each portion has a Key Takeaways section where you can get the TL;DR version.
If you want to skip to a particular step, the elements we'll cover are:
Step 0: Protecting your API with Authorization and Usage Plans
Vocabulary time: Service proxies vs. proxy integrations vs. proxy methods
Step 2: Transforming the request with the Integration Request
Let's get started!
Roadmap: The three basic parts
Before we get too far, let get oriented with three major parts of the API Gateway request lifecycle.
API Gateway is not the final destination for a particular HTTP request. Rather, it is an intermediary between a client that is making a request and the service that the client is consuming.
The most important element is the integration. I'll sometimes refer to it as a "backing integration" as well. This is the raison d'etre of the API request -- what the client is actually trying to do. It is outside of API Gateway itself. The integration is where API Gateway will route your request once it passes authorization and validation.
An integration could be a Lambda function that processes a payload. It could be an HTTP endpoint which is forwarded the request. It can even be another AWS service that is called directly by API Gateway.
The integration portion is shown with an obnoxious red border below:

The two other main elements in API Gateway are the request and the response flows. The request flow contains everything before the HTTP request hits the backing integration and is concerned with validating and preparing your request for your integration.
The response flow contains everything after the HTTP request hits your integration and deals with preparing the response to the client.
The request and response flows are indicated on the following diagram:

Thus, when an HTTP request comes to API Gateway, it will go through three elements:
- First, it will go through the request flow to authorize, validate, and transform the request.
- Second, it will go to the integration where the request will be handled by your service.
- Finally, it will go through the response flow to transform and prepare the response for the original client.
Keep these elements in mind as you work through the following sections.
Step 0: Protecting your API with Authorization and Usage Plans
The first step in the API Gateway lifecycle is authorization:

I've marked this at Step 0, rather than Step 1, as authorization is an optional feature of API Gateway. You can choose to skip auth in your API entirely, or you can opt to handle authorization in your integration backend.
That said, if you do want authorization in your API, putting it in API Gateway can be a smart choice for a number of reasons:
It consolidates your authentication logic to a single place;
It protects your downstream integration from unauthorized requests, saving you money and/or load on your resources.
It can be cached, reducing the number of hits on your authentication service.
Within this authorization step, there are two checks that apply -- the authorization check and the API key check.
Authorization with custom authorizers, Cognito, or IAM
The most common use of the authorization step in API Gateway is an actual authorization check. With this check, you look at some aspect of the request -- either an HTTP header or a querystring -- to identify the caller and either allow or reject the request based on whether the caller may invoke the API.
There are three methods for configuring an authorization check in API Gateway:
For a user-facing API, the latter two options are most commonly used.
The Cognito User Pool is a nice, clean integration if you are already using a User Pool for your authentication needs. You won't need to write any custom logic as you simply configure the required scopes needed for a particular API endpoint.
If you aren't using Cognito User Pools or if you need more fine-grained authorization needs, Lambda custom authorizers are the way to go. With custom authorizers, you can run any logic you run to authenticate and authorize the caller. You can even inject additional context into the request based on the identity of the caller.
For a larger breakdown of using custom authorizers, check out my Complete Guide to Custom Authorizers.
API keys and usage plans
The second element of the Authorization step is the API key check. You can configure API Gateway to provision API keys that must be passed as part of any request. API keys are passed using the x-api-key header, and API Gateway will reject requests without them.
While I've included API keys in the Authorization step, they are not meant to be used as the primary mode of authorization. API keys are not fine-grained ways to identify and authorize a user.
So what should an API key be used for? Rate limiting and throttling users.
AWS allows you to configure usage plans. You then associate API keys with a particular usage plan.
With a usage plan, you can configure two things: throttling limits and quota limits. Throttling limits specify how many requests per second are allowed for a particular usage plan. You can use this to prevent a caller from overwhelming your downstream resources.
Quota limits allow you to set a maximum number of requests over a particular time period, such as a day, a week, or a month. This allows you to enforce limits on a particular client. For example, if you are providing a paid API where a user gets a certain number of calls per month, you can use quota limits to enforce that limit.
Note that usage plans are limited to 300 per account per region by default, though you can request a limit increase if needed.
Key Takeaways from Step 0: Authorization
Here are the key takeaways from this section:
Authorization is a completely optional step. You don't need to include any authorization on your API.
Using authorization in API Gateway can protect your downstream resources from excess load.
You can authorize a request by using Cognito User Pools, AWS IAM, or a Lambda custom authorizer.
You can throttle a particular user by using API keys.
The authorization check runs before the API key check.
You may use just an authorizer, just an API key, both, or neither.
Step 1: Validation with Method Requests
Take a deep breath. We've already learned a lot, but we haven't even started step 1 yet.

In this step, we'll learn about method requests. Method requests are like the public interface of your API: they define what your endpoint expects, which elements are required, and more.
The method request step is Step 1 in our diagram:

In this step, you can validate the structure of your requests to API Gateway. By validating in API Gateway, you can reduce the amount of boilerplate you write in your backend integration.
We'll explore validation in two parts. First, we'll look to validating parameters like querystrings and HTTP headers. Then, we'll look at validating the request payload.
Validating Parameters
Your API may require certain headers, such as an Authorization header for authentication and authorization, or an If-Modified-Since header for making conditional requests. Similarly, you may use querystring parameters in your URL to filter the response or indicate pagination information.
With API Gateway method requests, you can specify these parameters and make them required if desired. If a client fails to provide the parameter, the client will receive a 400 Bad Request response with a payload like the following:
{
"message": "Missing required request parameters: [<parameter>]"
}
To enable request validation in the console, navigate to the Method Request section of the resource and method for which you want validation.

You'll need to set the Request Validator property up top as well as specify the required parameters down below. Be sure to deploy your API after making these changes.
However, you shouldn't be using the AWS console to manage your API Gateway deployments -- you should be using something like CloudFormation for infrastructure-as-code.
To configure request validation in CloudFormation, you'll need to do two things:
Create an AWS::ApiGateway::RequestValidator resource that is configured to validate request parameters.
On your AWS::ApiGateway::Method resource, use the validator you created as the
ValidatorRequestIdproperty, then specify the parameters to validate in theRequestParametersproperty.
Perform a deploy and voila! You have request parameter validation on your API Gateway.
Validating the Request Body using Request Models
In addition to validating headers and querystring parameters, you can also choose to validate the body of a request.
Validating the request body is a little trickier than validating headers, as you're dealing with a complex object rather than simple strings. However, this validation can greatly simplify your backend logic as you know you'll be receiving valid data.
To validate your request body, you'll first need to create a request model. A model is a JSON schema document that describes the expected shape of an object.
To register your model with CloudFormation, you'll need to create an AWS::ApiGateway::Model resource. You'll specify the expected Content-Type for the model as well as the JSON schema for the model.
Here's a simple example of an AWS::ApiGateway::Model resource:
UserModel:
Type: AWS::ApiGateway::Model
Properties:
RestApiId:
Ref: RestApi
ContentType: "application/json"
Description: "User Model"
Name: UserModel
Schema:
"$schema": "http://json-schema.org/draft-04/schema#"
title: UserModel
type: object
properties:
name:
type: string
age:
type: integer
username:
type: string
Once your model is created, you will need to add validation by setting the RequestModels property of your AWS::ApiGateway::Method resource. This property is a map of key-value pairs, where the key is a particular Content-Type and the value is the name of the model to validate for that Content-Type.
Finally, like with validation of request parameters, you'll need to configure an AWS::ApiGateway::RequestValidator resource that enables request body validation.
Key Takeaways from Method Requests
Here are the key takeaways from the method request step in API Gateway:
The method request step is primarily used for validation of the incoming request.
You can easily require certain headers and/or querystrings by specifying the name of the header or querystring.
You may choose to validate the request body as well. This requires submitting a JSON schema object as your model against which the request body will be validated.
To validate parameters or the request body, you must create a RequestValidator resource.
Vocabulary time: Service proxies vs. proxy integrations vs. proxy resources
We're going to take a quick break from learning about the API Gateway lifecycle to learn some vocabulary.
Specifically, we're going to learn about the word proxy.
And we're going to learn how the word proxy means three different things in API Gateway.
API Gateway has:
Proxy resources;
Proxy integrations; and
AWS service proxies.
Let's see what each of them are.
Proxy resources in API Gateway
The first kind of proxy is a proxy resource. A proxy resource is a like a catch-all HTTP path to handle a number of different HTTP requests.
The easiest way to understand this is by seeing it in action. There are two common ways to use a proxy resource.
The first way to use a proxy resource is to capture a variable part of your HTTP path. For example, perhaps you have a REST API that exposes a Users resource at /users/{userId}. Someone requesting /users/1234 would receive information on the user with ID of 1234, and someone requesting /users/5678 would receive the user with an ID of 5678.
Specifying the {userId} portion of your path is a proxy resource. You can even include multiple proxy elements in a path, such as /users/{userId}/orders/{orderId}.
The second way to use a proxy resource is as a greedy resource to capture all path values after the proxy indicator. To do this, you include a + in your proxy resource -- /{proxy+}.
This second method is used when you are doing all of your routing in your backing integration. This could be because you've put an entire Express application in a Lambda function or because you're using API Gateway as a frontend to an existing HTTP application.
Proxy integrations in API Gateway
In the next step, we'll talk about transforming your request to prepare it for your backing integration. This can be tedious and error-prone work using Velocity Template Language (VTL) (discussed more below).
But sometimes you don't need to transform your request. Maybe your request is fine just the way it is. In this case, API Gateway lets you use a proxy integration to skip the integration step altogether.
There are two types of proxy integrations: Lambda proxy and HTTP proxy. A Lambda proxy forwards your HTTP request to your Lambda function using a default mapping template. This can vastly reduce your development time when using API Gateway and Lambda.
Similarly, the HTTP proxy forwards the entire request to your backing HTTP endpoint. This can be useful if you want to add some features of API Gateway -- such as custom authorizers, usage plans, or input validation -- but you don't want to rewrite your application to work with a different format.
Both kinds of proxy integrations can be used with proxy methods to simplify your usage of API Gateway. At this point you're losing a lot of the higher-level features of API Gateway, but this can be right depending on your circumstances.
AWS Service Proxy integrations in API Gateway
The third and final kind of proxy is an AWS service proxy integration. This is when you use AWS API Gateway to forward a request directly to another AWS service. For example, you may use a service proxy to send HTTP payloads directly to an SNS topic or to insert items directly to DynamoDB.
A service proxy has a number of benefits. You can provide a cheap, low-mess way to ingest data from many distributed clients. By using an API Gateway service proxy, you can avoid running a full-time service whose sole purpose is to receive data and dump it into a different AWS service.
Key takeaways from the three kinds of proxies:
Proxy methods help you greedily grab HTTP paths to send to your integration;
Proxy integrations forward requests to your integration without writing a mapping template;
Service proxies are ways to connect API Gateway requests directly to other AWS services.
Step 2: Transforming the request with the Integration Request
Vocab time is over, let's get back on track.
We've authenticated our request. We've validated its structure. Now it's time to transform our request to make it ready for use by our integration:

Note that if you're using the Lambda Proxy or HTTP Proxy discussed in the previous section on proxy integrations, you can skip this step entirely! However, the time you save here by avoiding integration request configuration can mean additional compute and load in your backing integration.
The integration request step is about transformation. Our request has come in from our client, but we may need to reshape that request to make it ready for our backend integration.
There are a number of reasons the shape of the request for the client is not the shape of the request needed by your integration:
You're using API Gateway to provide a more user-friendly interface on top of an older API. For this, you may need to translate an
application/jsonpayload from your client into anapplication/xmlpayload for your integration.The client may not know information needed for the integration request. For example, if you're using API Gateway as a service proxy to another AWS resource, the client may not know the SNS topic or Kinesis stream to which you're proxying requests.
You want to remove request information before forwarding to the backend. Perhaps you have a custom authorizer that requires an
Authorizationheader, but you don't want this header exposed to your backend integration. After the request has successfully passed authorization, you can strip it out of the request before forwarding to the integration.
With these use cases in mind, let's take a look at transforming our request with VTL.
Writing Mapping Templates with VTL
To transform the initial request into your integration request, you need to write a mapping template. Like request body validation, a mapping template is associated with a particular Content-Type for an HTTP request.
Mapping templates are written using the Velocity Template Language (VTL) VTL has an ... interesting ... syntax that is somewhere between declarative templates and imperative programming.
On the more declarative end, you can write a VTL template like the following (taken from my post on an API Gateway service proxy integration):
"Action=Publish
&TopicArn=$util.urlEncode('<yourTopicArn>')
&Message=$util.urlEncode($input.body)"
This example returns a simple x-www-form-urlencoded string that uses some utility methods to URL encode some other properties. It uses a hard-coded SNS Topic ARN that only API Gateway knows, as well as the request body (accessed using $input.body).
You can use a more imperative approach in your mapping template as well, such as this example from the official docs:
#set($inputRoot = $input.path('$'))
{
"DueDate": "$inputRoot.DueDate",
"Balance": $inputRoot.Balance,
"DocNumber": "$inputRoot.DocNumber",
"Status": "$inputRoot.Status",
"Line": [
#foreach($elem in $inputRoot.Line)
{
"Description": "$elem.Description",
"Amount": $elem.Amount,
"DetailType": "$elem.DetailType",
"ExpenseDetail": {
"Customer": {
"value": "$elem.ExpenseDetail.Customer.value",
"name": "$elem.ExpenseDetail.Customer.name"
},
"Ref": {
"value": "$elem.ExpenseDetail.Ref.value",
"name": "$elem.ExpenseDetail.Ref.name"
},
"Account": {
"value": "$elem.ExpenseDetail.Account.value",
"name": "$elem.ExpenseDetail.Account.name"
},
"LineStatus": "$elem.ExpenseDetail.LineStatus"
}
}#if($foreach.hasNext),#end
#end
],
"Vendor": {
"value": "$inputRoot.Vendor.value",
"name": "$inputRoot.Vendor.name"
},
"APRef": {
"value": "$inputRoot.APRef.value",
"name": "$inputRoot.APRef.name"
},
"TotalAmt": $inputRoot.TotalAmt
}
As you can see, this is both powerful and complex. Notice that there's some variable assignment, a for-loop, as well as an if-statement, all of which can greatly complicate the logic.
The amount of logic you put in your mapping templates comes down to your needs and your personal preferences. If the backend integration is not one that you control, such as an AWS service proxy or an existing legacy API, writing a complex VTL template may be your only option.
On the other hand, if you control your integration, such as in a Lambda function or an easier-to-change HTTP endpoint, you may want to do the body transformations in your endpoint's logic where it can be easily tested using your native tooling. If this is the case, you can use the Lambda proxy integration discussed in the previous section.
I'm not going to get deep into the mapping template reference because, quite frankly, I barely understand it. Check out the mapping template reference docs for additional information.
API Gateway integration passthrough behavior
In the last section, we saw how to define mapping templates for various Content-Types on your API Gateway method. Let's now take a look at the passthrough behavior of your method.
The passthrough behavior for your method describes how API Gateway will handle a request that does not have a mapping template defined for its Content-Type.
There are three kinds of passthrough behaviors:
WHEN_NO_MATCH: This is the most permissive option. If a request comes in with a Content-Type that does not have a mapping template, API Gateway will forward the request to the integration without changing the request body.
NEVER: This is the most restrictive option. If there is no mapping template that matches the Content-Type of this request, the request will be rejected.
WHEN_NO_TEMPLATES: This option passes the request body through only if no mapping templates at all have been defined for this resource. I find this to be the oddest option -- I prefer to be explicit and pass through with WHEN_NO_MATCH or reject with NEVER. Who cares whether a template for a completely different Content-Type has been defined? (Note: Ben Kehoe gave a reasonable answer of why to use WHEN_NO_TEMPLATES that involves method-wide defaults).
If you're doing the work to write a mapping template, you're probably offloading request transformation in your backing integration. In that case, I would recommend the NEVER passthrough behavior.
However, if you're handling all transformation in your backend or if your request body is already in the proper shape due to the validation in the method request, the WHEN_NO_MATCH is a simpler option.
Key Takeaways for Integration Requests
Here are the key takeaways for the integration request step:
The integration request step is for transforming data to arrange it in the proper shape for your backend.
If you're using an HTTP Proxy or Lambda Proxy integration, you do not configure an integration request.
You can transform the request object by writing mapping templates using the Velocity Template Language.
Mapping templates are configured for a particular Content-Type of the request.
For requests that have a Content-Type without a configured mapping template, you need to set the passthrough behavior to state how an unspecified Content-Type should be handled.
Handling Errors with Gateway Responses
As we've walked through the request flow, we've seen a number of ways our request could get rejected before hitting our integration.
Perhaps the authentication token was missing or invalid.
Maybe the usage plan had already exceeded its limit.
Possibly the client forgot to include a required querystring or the request payload didn't match our model.
Or even (believe me, this can happen), you made a mistake in your VTL mapping template which caused an error.
In this section, we're going to learn how to handle errors in any of the steps prior to your backing integration. These errors, whether planned or unplanned, are handled with Gateway Responses.
Let's see how they work.
Gateway Response Types
API Gateway provides a set of default Gateway Response Types. These response types are used for specific errors in API Gateway when a request fails before the backend integration.
Each gateway response type is made up of four elements:
Response type: The response type indicates the kind of failure that happens. This could be something like a request body that doesn't match the model in your method request (response type of
BAD_REQUEST_BODY) or an unsupported content type (response type ofINVALID_MEDIA_TYPE).Status code: The status code represents the status code that will be returned to the client for this response type. Each response type has a default status code that will be returned, but you may override it with a custom status code.
Response parameters: You may use custom response parameters to return headers in your error response.
Response templates: Similar to integration requests, you can construct a request body to send back with your error. You don't get the full range of VTL templates here -- you can only use basic variable substitution from the
contextobject on your request.
API Gateway has default configurations for each of the response types, but you may choose to override each of the response types with your own status codes and responses.
Some common reasons to override the responses are:
To add CORS headers to invalid responses;
To add additional information on why the request failed and how to fix it;
To hide implementation details of your API by moving from a specific failure to a more general failure.
Key takeaways from Gateway Responses:
Gateway responses are used to handle errors before a request hits your backing integration.
API Gateway has a number of default gateway responses for various failure modes, but you may override the status code and response details of any gateway response.
You can customize the a gateway response body similar to an integration request but without full VTL access.
Integration Intermezzo
Yeehaw, our request has made it to our integration!
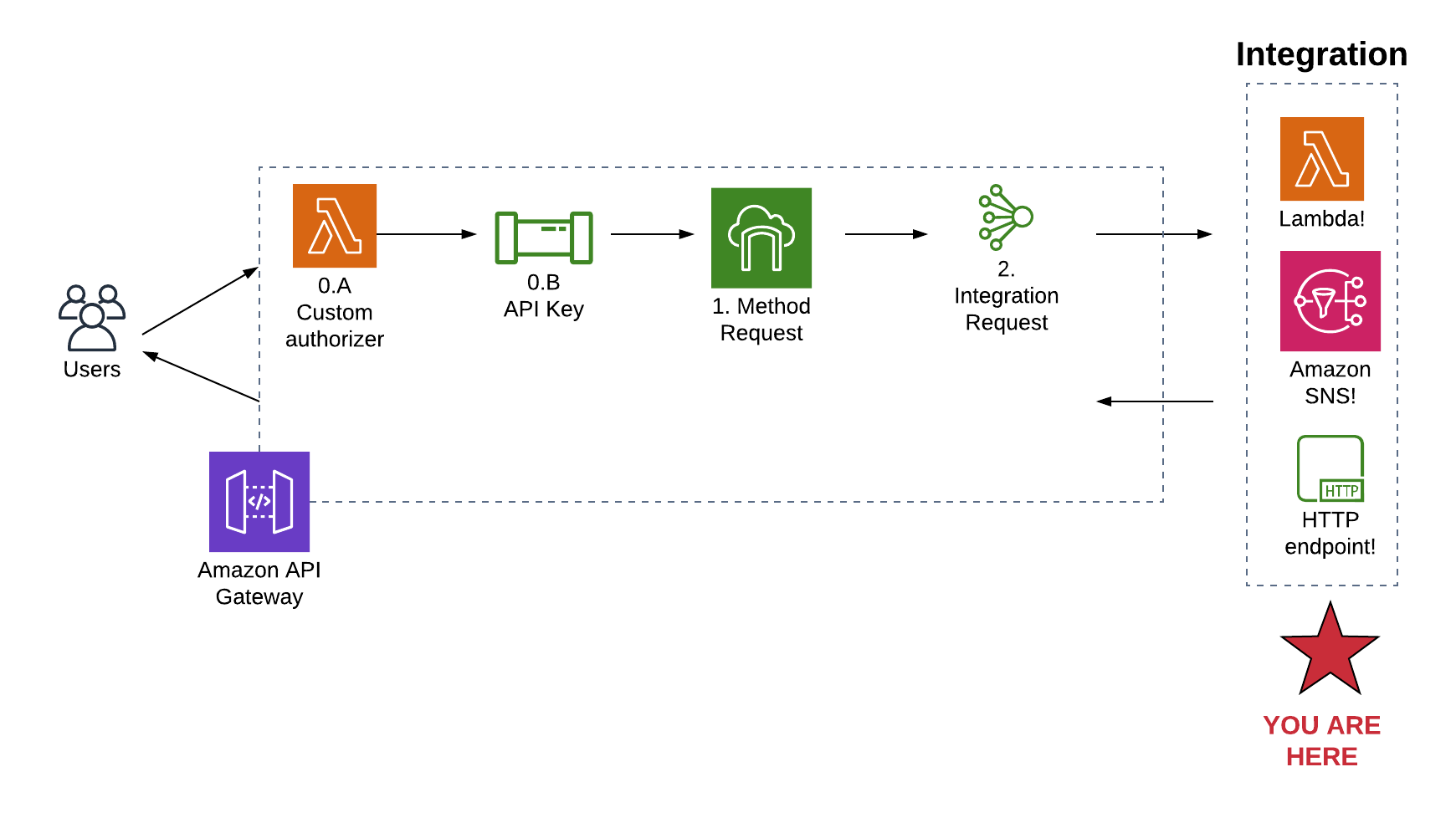
We made it through the entire request flow. This is where we get to do all the fun stuff with the request -- save a record to a database, drop an event into a stream, or hit an external API.
But our learning isn't done yet. Fortunately, the return trip for your request is much quicker. Buckle up, and let's finish this thing.
Step 3: Handling your response with Integration Responses
We're past the integration and our API request is making the return leg of its journey.
The first stop is the Integration Response:

The integration response is a way to internally standardize the response from our integration into something that can be handled next, by our method response. It's essentially the inverse of the integration request -- we're serving as the interface between our integration and API Gateway by transforming the request as needed.
If you are using a proxy integration, like Lambda proxy or HTTP proxy, you won't configure an integration response. Your integration will need to return a response in the format required by API Gateway to pass along to the originating client.
Like the integration request, we'll be using VTL again in the integration response section. However, there are some subtle differences in the full integration response workflow.
Identifying the response status code with regex
When configuring integration responses, you first need to provide a regex pattern to identify the response type. This will help you determine whether your integration had an error and what type of error if so.
If your integration is a Lambda function, the regex will run on the error message of your Lambda (if any). For example, you could use the regex of ".*Unauthorized.*" to capture a 401 Unauthorized status code.
If your integration is an HTTP proxy or an AWS service proxy, you will write a regex for the status code returned. For example, if you wanted to catch all 5XX errors, including 502 Bad Gateway and 504 Gateway Timeout, you could use a status code regex of "5\d{2}" to capture all 5XX errors and return a general 500 Internal Server Error.
Integration Response Mapping Templates
Like integration requests, you have the option to write VTL mapping templates to transform your integration responses.
Your VTL mapping templates are again based on Content-Type, and they are tied to a particular regex mapping for your status code. The flow looks as follows:
Determine the status code by using the regex matches;
Once a status code is determined, look for a mapping template based on the Content-Type within that status code configuration.
To configure your integration responses, you need to get pretty deep in your CloudFormation. The AWS::ApiGateway::Method resource has an Integration property on it. On that Integration object, there is an IntegrationResponses property which takes an array of IntegrationResponse objects. This configuration can be a little hairy on the initial setup, but it shouldn't change much after that.
Key Takeaways from Integration Responses
Integration responses are about transforming the response from your backing integration into something that API Gateway can handle.
If you're using a proxy integration, you will not configure an integration response.
You use a regex pattern to identify the status code of your response.
If you're using a Lambda integration, the regex pattern is applied to a Lambda error message. If you're using an HTTP or AWS service proxy integration, the regex pattern is applied to the status code.
Once a status code is determined, you may transform the response using a VTL template, just like in the integration request.
Step 4: Standardizing your responses with Method Responses
Note: This section does not apply if you are using the Lambda proxy or HTTP proxy integration.
We're so close. The last step in the API Gateway response flow is to creating your method responses.

Method responses are similar to method requests in that they are responsible for validating and standardization. Rather than validating the input from a client like a method request, they are validating the output to a client.
Method responses are responsible for two things:
Defining the status codes that will be returned by your API.
Defining the response bodies that are returned by your API.
Defining the method response bodies can be particularly helpful if you want to generate a strongly-typed SDK for your API, such as to use with Java or C#. By specifying the response codes and bodies that will be returned, your applications can interact with your API more easily.
Defining status codes in method responses
By default, the only status code that API Gateway will return is a 200 OK. If you want to use HTTP status codes to provide sanity around your HTTP responses, you'll need to define them in a method response.
Once you've defined your method response, then you create your integration response in the previous section to use a regex to map a particular response to your status code.
This process may a little backward -- you need to create the method response before your integration response, even though the integration response happens first in the flow. However, it makes sense if you think about it like the method response defining the response interface for your API. First you declare the interface for your API, then you write the integration response implementation to satisfy it.
Declaring response bodies using models
In Step 1 above, we saw how you can use JSON schema models to validate the incoming request body in API Gateway. You can do the same thing with your response body.
API Gateway allows you to generate SDKs to consume your API. This can be a great way to quickly start using your API in your application.
If you're using a strongly-typed language in your application, adding response models will make the SDK much more useful as you will have strongly-typed response bodies.
If you're not using a strongly-typed language or aren't generating SDKs, you may not find as much value from specifying models for the response bodies.
Key Takeaways from method responses
Method responses are not applicable if you're using a Lambda proxy or HTTP proxy integration.
API Gateway only returns a
200 OKstatus code by default. You can add additional status codes by adding method responses.You must create your method responses before you can use a given status code in an integration response.
You can specify models for your response bodies that will help when generating an SDK for a strongly-typed language.
Conclusion
We covered a lot of ground in this one. We walked through the entire request flow of API Gateway, including authorization, API keys, method responses, and integration responses. We saw how to handle errors with gateway responses and took a vocabulary lesson for the three kinds of proxies in API Gateway. Finally, we saw how the response flow worked by looking at integration and method responses.
Amazingly, there's still a ton of ground to cover in API Gateway. We barely scratched the service with mapping templates. And we didn't talk about documenting or publishing your API in API Gateway. Another post, another day.
Questions on this post? Leave them in the comments below or shoot me an email.