
One of the core complaints I hear about DynamoDB is that it can't be used for critical applications because it only provides eventual consistency.
It's true that eventual consistency can add complications to your application, but I've found these problems can be handled in most situations. Further, even your "strongly consistent" relational databases can result in issues if you're not careful about isolation or your choice of ORM. Finally, the benefits from accepting a bit of eventual consistency can be pretty big.
In this post, I want to dispel some of the fear around eventual consistency in DynamoDB.
We'll walk through this in three different sections:
- Background on eventual consistency
- The three flavors of eventual consistency in DynamoDB
- Dealing with the effects of eventual consistency
My hope is that you can use this to make a more informed decision about when and how you can handle eventual consistency in your application.
Background
Before we get started, let's set the boundaries for what we're going to discuss today.
There's a lot of confusion around eventual consistency. Part of this is because the area of database and distributed system consistency is confusing -- so much so, that I wrote a huge post on the different concepts of consistency before I could write this one. Amazingly, that post covered three types of consistency, and the idea of 'eventual consistency' was not one of them. If the concepts in this background are confusing to you, you should read that post first.
At a very high level, the notion of "eventual consistency" refers to a distributed systems model where, to quote Wikipedia, "if no new updates are made to a given data item, eventually all accesses to that item will return the last updated value."
Note that this definition talks about what eventual consistency can promise, but the interesting part is what it doesn't promise. It doesn't promise that any read of a data item will show the most recent updates to that item. This is the core downside of eventual consistency -- you could update an item with one request, then fail to see those updates with a subsequent request.
With that in mind, let's note three key aspects about eventual consistency. These aspects are broadly applicable, but I will use a DynamoDB focus in discussing them.
Eventual consistency is about replication
Fundamentally, eventual consistency is an issue of replication.
In a single-node database, you don't have to worry about eventual consistency. Writes and reads are coming to the same instance, so it should be able to provide a consistent view of a single data item.
Once you start to replicate your data to multiple nodes, the story changes. Now, when a write comes to a node, you need to figure out how to efficiently communicate that write to the other nodes. Further, if you allow reads from the other nodes, then you think about the PACELC tradeoff discussed in the next section.
Replication adds some complexity around eventual consistency, but replication can be a good thing as well! There are a number of reasons you may want to replicate your data to multiple places, such as:
Redundancy. Adding replicas allows for redundancy in case your primary instance fails. In this case, you're not necessarily reading from your replicas -- you're simply maintaining a hot standby in the event of failure. Thus, there are no eventual consistency implications (outside of failure scenarios) that are implicated solely due to redundancy. This is the default mode for MongoDB replicas, which direct all read requests to the primary node unless otherwise configured.
Increase throughput. A second reason to add replication is to increase your processing throughput. In this case, you may direct all write operations to your primary node but reads can go to your secondary nodes. This is the approach used when adding read replicas to your relational database. By increasing the nodes available for read traffic, you're able to handle more requests per second. However, you do add the eventual consistency issues discussed in this post.
Get data closer to users. A third reason for replication is to move data closer to your users. Your users may be global, but often your database is in a central location. If that's the case, the network latency to your database is likely the slowest part of a request. By globally distributing your data, you can vastly reduce client-side latency. This is the approach taken by Fly.io with global Postgres. This does implicate eventual consistency issues as well.
Note that these reasons aren't mutually exclusive! All three of these are at play with DynamoDB. Adding replicas in different availability zones enhances availability through redundancy. Because each replica can receive read requests, they also increase throughput. Finally, if you use DynamoDB Global Tables, you can put your data closer to your users.
Eventual consistency is not (only) about CAP
When people think about eventual consistency, they often jump straight to the CAP theorem. And the CAP theorem is relevant when thinking about eventual consistency. If you choose an AP system, you probably have some process to reconcile the data on disparate nodes once the network partition is healed.
But the CAP theorem is limited. It only applies during times of failure and only during a specific type of failure -- network partitions between nodes. (See this post for more on when CAP applies).
Most of the time, your application is going to be running as intended. During that time, if you're allowing reads from your secondary nodes, you have to think about a different tradeoff -- one between latency and consistency. This is the second half of the PACELC theorem, which I discussed further here.
Let's think about this with a quick example. Imagine you have a three-node system. Node A is the primary and handles the writes, but reads can be handled by any of the nodes.

When a write comes to your primary node, you have a range of options on how to handle it.
You could require that all three nodes acknowledge durably committing the update before acknowledging the write to the client. This gives you the strongest consistency, as all writes must be agreed upon by all nodes before accepting. However, it also increases latency, as you need to communicate with these remote nodes and wait for the slowest one to respond. You can think of this as comparable to a RDBMS with synchronous replication to read replicas.
On the other end of the spectrum, you could only commit the write to the primary node before acknowledging to the client. The primary node could then send the updates to the replica nodes asynchronously. This has much lower write latency for clients at the cost of more data inconsistencies on reads. This is more comparable to asynchronous read replicas with a relational database or with MongoDB's writeConcern: 1 setting.
More in the middle is something like MongoDB's writeConcern: "majority" setting, where the write must be committed to a majority of nodes before returning.
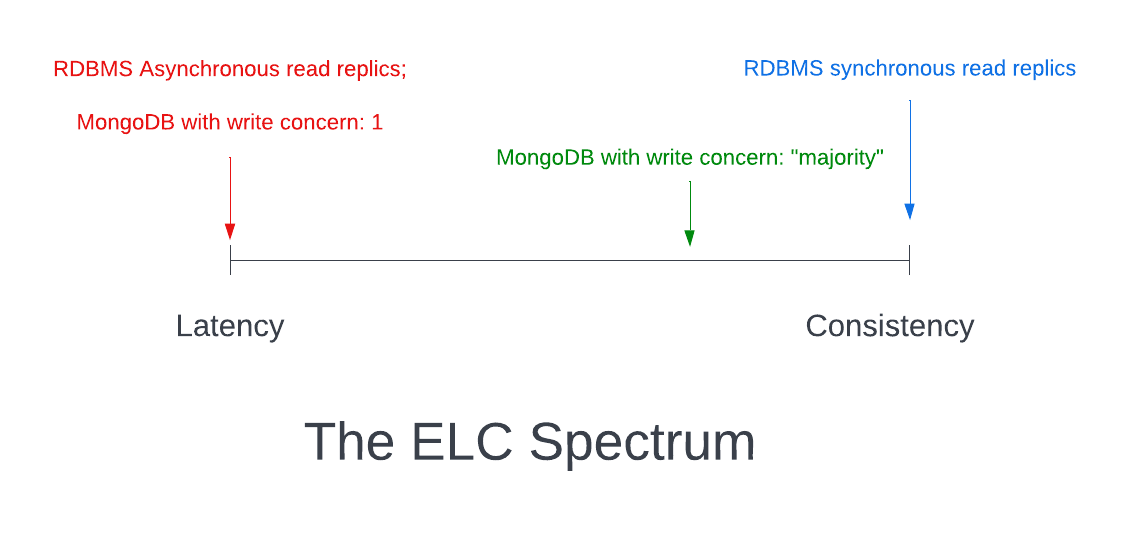
In reviewing the different flavors of eventual consistency below, we'll talk about where each one fits on the spectrum.
Eventual consistency is (usually) about reads
A final point to keep in mind is that eventual consistency is almost always a read problem but not a write problem.
Most replicated databases use a primary-replica setup where any piece of data has a primary node and one or more replica nodes. The primary node is responsible for all write operations and will send updates to the replica. This means you don't have an eventual consistency issue when writing data -- you'll always be operating against the latest version of the data when writing.
This is important later on when we discuss strategies for dealing with eventual consistency.
That said, some databases do allow for a multiple primary setup. Amazon Aurora has multi-master clusters where any of the instances can handle write operations. Similarly, DynamoDB Global Tables are essentially a multi-primary system where each enabled region has a primary node.
Using a multi-primary system increases complexity around eventual consistency and can lead to subtle bugs. We'll talk about this later.
The Three Flavors of Eventual Consistency in DynamoDB
With our basic notes in mind, let's understand the three flavors of eventual consistency in DynamoDB. Those flavors are:
- Eventual consistency on your main table (and local secondary indexes);
- Eventual consistency on global secondary indexes;
- Eventual consistency on DynamoDB global tables.
We'll handle these in order.
Eventual consistency on your main table
First, let's talk about eventual consistency on your main table.
Quick sidebar: DynamoDB tables have a primary key that uniquely identify each item. The DynamoDB API strongly pushes you toward using the primary key for your data access. But often you have items that need to be accessed in multiple distinct ways. With secondary indexes, you accomodate this. You can create secondary indexes with a different primary key, and DynamoDB will replicate your data into the secondary index with this new primary key structure. Finally, note that you can only make reads against your secondary index -- all writes must go through your main table.
Your main table is an interesting case in DynamoDB as you have the option between using strongly consistent reads or eventually consistent reads. To understand why, let's understand DynamoDB's underlying infrastructure and what happens when a write request comes in.
First, you should know that, under the hood, DynamoDB segments your data onto multiple partitions. DynamoDB will assign a record to a specific partition based on the partition key of your table, and each record belongs to one and only one partition.

But that's not the end of the story. Each partition includes three nodes: a primary and two replicas. The primary node is the only one that can handle writes, but any of the replicas can serve reads.
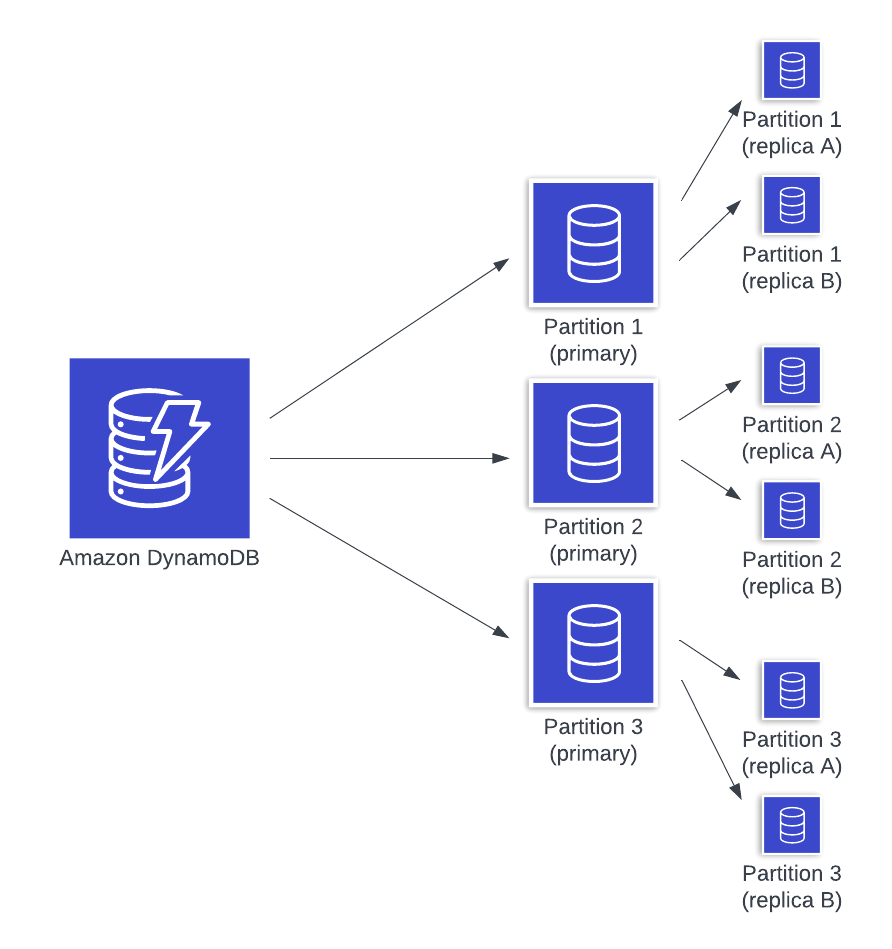
When a write comes to a DynamoDB table, the request router will use the partition key to direct it to the primary node for the given key. The primary node will tentatively apply the write if any write conditions are met. Then it will submit the write to both replica nodes. As soon as one of the replicas responds with a successful write, the primary node will return a successful response to the client.
By ensuring that a majority of the nodes have committed the write, DynamoDB is increasing the durability of the write. Now, even if the primary node fails immediately after the write request, it has been durably committed to another node to preserve the write.
You can also see where the potential for an inconsistent read comes in. Imagine our write request is accepted after the primary and Replica A have recorded it. When a read request comes in, it could go to our primary or either of the two replicas. If it chooses the lagging Replica B, there's a possibility we could receive a stale read that does not include the latest updates to the item.
In effect, DynamoDB chooses an intermediate position on the latency-consistency continuum. It doesn't go for strong consistency by durably writing to all nodes, but it also doesn't take latency to the lowest limit by writing to only one node. Part of this is due to the durability benefits of writing to multiple nodes, but it's relevant nonetheless.

Two final notes to wrap up this section.
First, while a stale read is possible on your main table, it's fairly unlikely. Remember that DynamoDB will randomly choose one of the three nodes to read from to handle a read request. Because a write will be committed to two of the three nodes before being acknowledged, this means there's a 66% chance you'll hit one of the "strongly consistent" nodes anyway.
Further, the lagging third node probably isn't that far behind in the normal case. The primary sent the write operation to both replicas at the same time. While it won't wait for the second replica to respond, it's probably milliseconds behind at most. This is exactly what I found in some basic testing as well.
Second, while I've been talking about your main table in this section, the same principles apply to local secondary indexes. Some of the nuances around local secondary indexes require another post, but items in a local secondary index are kept on the same partition as the items in the main table and thus have the same replication behavior.
Eventual consistency on global secondary indexes
Now that we've covered the standard case with our main table, let's move on to the second flavor of eventual consistency -- that of global secondary indexes.
Unlike your main table or local secondary indexes, you cannot opt in to strongly consistent reads for your global secondary indexes. To understand why, we'll again look to the infrastructure underlying the implementation.
We talked in the previous section about how DynamoDB partitions your data using the partition key of your data. When you create a global secondary index on your table, DynamoDB creates completely separate partition infrastructure to handle your global secondary index:

Note that this separate infrastructure for secondary indexes is different than how other NoSQL databases handle it. With MongoDB, for example, additional indexes are implemented on each of the existing shards holding your data.
Why does DynamoDB place global secondary indexes on new partitions? It all flows from DynamoDB's laser focus on consistent, predictable queries.
DynamoDB wants your response times to be consistent no matter the size of your database or the number of concurrent queries. One key way it does this is via its partitioning scheme using the partition key so that it can quickly find the right ~10GB partition that holds your requested data.
But a global secondary index can have a different partition key than your main table. If DynamoDB didn't reindex your data, then a query to a global secondary index would require querying every single partition in your table to answer the query. This is exactly what MongoDB does -- if you have a query that does not use the shard key on your collection, it will broadcast to every shard in your cluster.
Ok, so we know the choice DynamoDB makes in placing your global secondary indexes on separate partitions. Why does this mean we can't get strong consistency from these separate partitions?
Recall our tradeoff between latency and consistency. To get strong consistency from a given node, we must ensure the write is committed to the node before the write is acknowledged. Thus, our table would need to not only write to the primary and one replica of our main table, but also two nodes for each global secondary index as well!
With one global secondary index, that might not sound so bad -- what's a few milliseconds between friends? But you can have up to 20 global secondary indexes by default, and you can even request a limit increase to have more!
You don't want your writes hung up on acknowledgements from 10+ nodes, each of which has their own provisioned capacity and instance failures. This would vastly reduce the benefit of global secondary indexes.
Instead, DynamoDB uses asynchronous replication to global secondary indexes. When a write comes in, it is not only committed to two of the three main table nodes, but it also adds a record of the operation to an internal queue. At this point, the write can be acknowledged to the client. In the background, a service is processing that queue to update the global secondary indexes.
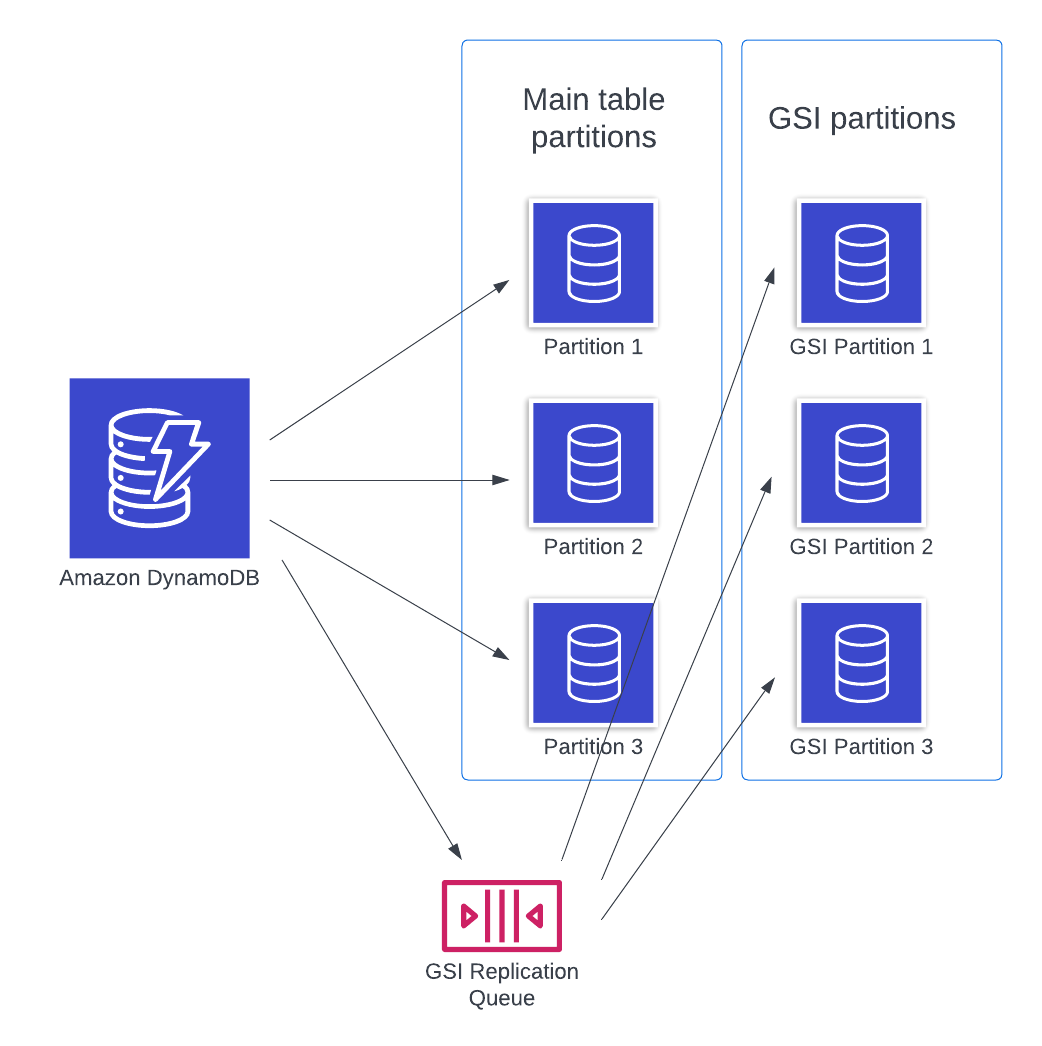
Notice where global secondary indexes fall on the latency-consistency spectrum. They optimize heavily for write latency at the expense of consistency.

Further, and more importantly, notice the difference in flavor of eventual consistent reads on your main table as compared to reads from your global secondary index. The replication lag on your main table is likely to be barely perceptible in the normal course of business, whereas the replication lag for global secondary indexes will be more noticeable.
Finally, the replication lag on global secondary indexes can be influenced by your own actions. Global secondary indexes have capacity that is separate from your main table. If you don't provision enough capacity, or if you exceed partition throughput limits for your index, the lag can be even longer. This is different from your main table where exceeding provisioned capacity or partition throughput limits will result in an error on the write request itself.
Eventual consistency on DynamoDB Global Tables
When I first conceived of this post, I was going to discuss the Two Flavors of Eventual Consistency in DynamoDB, as I wanted to make the key point about the difference in replication lag between your main table and global secondary indexes. But as I started to write, I realized there's a third flavor of eventual consistency in DynamoDB -- that of cross-region replication using DynamoDB Global Tables.
As a quick summary: DynamoDB Global Tables are a fully managed way to replicate your tables across multiple regions. This can be used for both the redundancy reason for replication, as you have some resiliency in the face of region failure, as well as the "get data closer to users" reason, as users can be routed to the region nearest them.
In a way, the infrastructure for DynamoDB Global Tables is similar to the infrastructure for global secondary indexes. When a write is received in one region, it is durably committed to two of the three nodes on the main table for the region and the write is acknowledged to the client. Then, it is asynchronously replicated to separate infrastructure. Rather than being a different set of partitions in the same region, the target infrastructure is a separate table in a different region.

Similar to global secondary indexes, Global Tables optimize for latency on the latency-consistency spectrum. However, there are two additional notes to consider as compared to global secondary indexes.
First, the replication latency to Global Tables is likely to be longer than that to global secondary indexes. Regions are significantly further apart than instances in the same datacenter, and network latency starts to dominate. P99 latencies across regions can easily be 100 - 200 milliseconds, so you should anticipate your replication being affected accordingly.
Second, using Global Tables introduces write-based consistency issues into your application. I mentioned earlier that eventual consistency is mostly a read-based problem, but that's not the case with Global Tables. You can write to both regions, and writes will be replicated from one region to another.
This can result in a few different problems in your application, which we'll talk about in the next section.
Dealing with the effects of eventual consistency
Now that we know the different types of eventual consistency in DynamoDB, let's talk about some strategies for dealing with eventual consistency. As always, you must understand the requirements of your application to determine which strategies work best for you.
Know the general latency characteristics for your flavor of eventual consistency
As discussed above, there are three flavors of eventual consistency in DynamoDB, and these flavors have very different replication lags. You may find that, practically, you rarely see the effects of eventual consistency in your application.
A common preference around consistency is something called "read your writes". This basically says that if a process makes a write and later performs a read, that read should reflect the previous write. It doesn't offer guarantees about reads from other processes, but it at least offers some sanity for a single workflow.
If your database allows you to direct operations to specific nodes, then a process can handle this by reading from the same server from which it wrote. With a load-balanced NoSQL database like DynamoDB, you don't get a choice from which server you read from. However, we can get a sense of how likely it is that I will get "read your writes" behavior from our different flavors of eventual consistency.
I did some basic testing of "read your writes" behavior against your main table and a global secondary index. You can read the full results and methodology in the GitHub repo here, but the high-level takeaways are:
- For eventually consistent reads made to a main table immediately after the write returned, 99.5% of them returned a consistent view of the item. This increased to 100% with a 100 millisecond delay between receiving the write and making the read.
- For reads to a global secondary index immediately after a write, 96.54% of them returned a consistent view of the item. This increased to 99.53% with a 10 millisecond delay and 99.72% with a 100 millisecond delay.
As you can see, even an eventually consistent read against a main table is going to get darn close to 'read your write' consistency in the vast majority of cases.
... but don't count on the general latency characteristics!
While understanding the general characteristics is useful, you shouldn't rely on this. As Ben Kehoe notes:
Ask me in person sometime about the ticket our devs opened after they built in an assumption of a maximum time for eventual consistency on DynamoDB
— Ben Kehoe (@ben11kehoe) July 12, 2022
The tests above are very basic tests in standard operation. You shouldn't expect these results in all scenarios.
I would expect the main table results to be more bounded than the global secondary index results, given that you still need 2 out of 3 to commit the write, and a flapping third node is likely to be replaced quickly if needed. In fact, a new paper on DynamoDB talks about how DynamoDB uses log-only replicas to keep write latency low and durability high in the event of partition failures.
A global secondary index, on the other hand, has more potential failure modes, including ones of your own making (underprovisioned throughput or exceeding partition throughput limits).
Use write conditions to guarantee consistency
As mentioned in the background, eventual consistency is mostly a read-based problem (check the next point for a caveat here). All writes to DynamoDB are happening against the latest version of the item. When making a write, you can include a ConditionExpression in your operation that must evaluate to True in order for the write to process.
The canonical example of potential problems with eventual consistency is a bank transaction -- what happens if I read a bank balance that is out of date, then approve a transaction based on the stale balance?
You can avoid this problem with the use of ConditionExpressions. Your ConditionExpression could require that the balance of the account is greater than the amount of the requested transaction in order to proceed. You can even combine multiple operations, each with their own ConditionExpressions, into a DynamoDB transaction in order to make these changes to multiple bank accounts with ACID semantics.
Amazingly, you're not necessarily going to avoid these issues with a relational database! Todd Warszawski and Peter Bailis have a fun paper showing how isolation levels below serializable can result in concurrency bugs during transactions. Peter Bailis and others have another fun paper showing how ORMs implement concurrency-control mechanisms that fail in subtle ways. I'm not saying this to scare you or raise FUD, but more to iterate that you really need to understand your infrastructure and your dependencies to avoid these issues altogether.
Write conditions won't save you from all your problems with eventual consistency, but they can help you avoid persisting data in inconsistent or invalid states. Look into strategies like pessimistic concurrency (aka locking), optimistic concurrency (aka version checking), or simply asserting data constraints in your write operations.
Avoid multi-region writes where possible
Let's address the caveat from the previous section. While eventual consistency is mostly a read problem, it can become a write problem if you're using DynamoDB Global Tables. Now you have multiple regions, each able to accept writes that are asynchronously replicated to other regions.
There are two sources of potential issues with writing to multiple regions.
First, you could lose writes that occur nearly simultaneously. Imagine a write in Region A that updates attribute X, while a concurrent write in Region B updates attribute Y. In theory, both of these writes can succeed, and DynamoDB will do its best to reconcile concurrent writes. However, you could find yourself losing updates in specific situations.
Second, you could assert write conditions that are true in your region's copy of the data but that are false in another region's (yet-to-be-replicated) copy. Condition expressions and DynamoDB Transactions are consistent in a single region only, so writing in multiple regions can add problems.
When using DynamoDB Global Tables, I generally recommend users only write an item in a particular region. For many, that means choosing a "write" region and directing all writes there, even if the latency is higher. For some use cases, individual items may naturally be correlated with specific regions and thus you can ensure that each write will only ever be written in a single region.
Conclusion
In this post, I hope we dispelled some of your fear about eventual consistency. First, we learned some background about eventual consistency generally. Then, we looked at the three flavors of eventual consistency in DynamoDB. As part of this, we developed our mental models of DynamoDB's underlying infrastructure to understand why the three flavors are different. Finally, we looked at some strategies for dealing with eventual consistency in DynamoDB.
If you have any questions or corrections for this post, please leave a note below or email me directly!