
Prefer video? View this post on YouTube!
DynamoDB powers some of the highest-traffic systems in the world, including Amazon.com's shopping cart, real-time bidding for ad platforms, and low-latency gaming applications. They use DynamoDB because of its fast, consistent performance at any scale.
Before I understood DynamoDB, I thought AWS had a giant supercomputer that was faster than everything else out there. Turns out that's not true. They're not defying the laws of physics -- they're using basic computer science principles to provide the consistent, predictable scaling properties of DynamoDB.
In this post, we'll take a deep look at DynamoDB partitions -- what they are, why they matter, and how they should affect your data modeling. The most important reason to learn about DynamoDB partitions is because it will shape your understanding of why DynamoDB acts as it does. At first glance, the DynamoDB API feels unnecessarily restrictive and the principles of single-table design seem bizarre. Once you understand DynamoDB partitions, you'll see why these things are necessary.
If you want to skip to specific sections, this post covers:
- Background on DynamoDB partitions
- How partitions do (and don't) matter in DynamoDB
- How partitions affect data modeling in DynamoDB
Let's get started!
Background on DynamoDB partitions
To begin, let's understand the basics of partitions in DynamoDB. And before we do that, we need to review some basics about DynamoDB tables.
DynamoDB is a schemaless database, which means DynamoDB itself won't validate the shape of the items you write into a table. Yet a DynamoDB table is not totally without form. When creating a DynamoDB table, you must specify a primary key. Each item that you write into your table must include the primary key, and the primary key must uniquely identify each item.
There are two types of primary keys in DynamoDB. First is the simple primary key, which consists of a single element called the partition key. The image below shows an example of a table with a simple primary key:
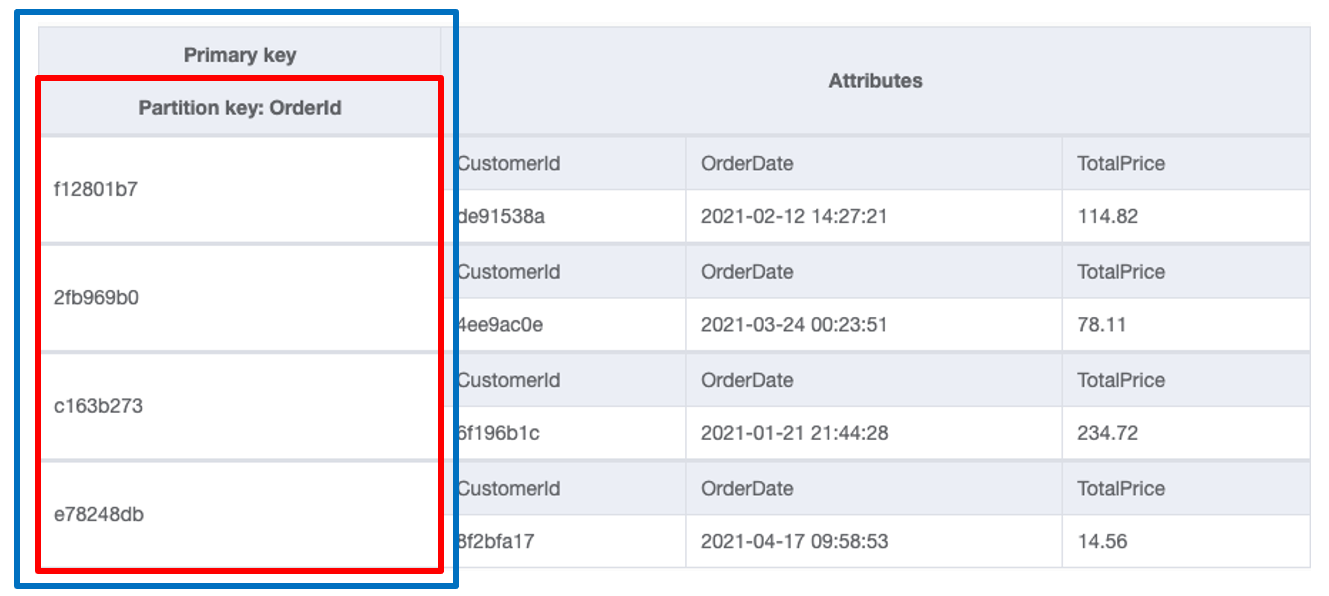
This table is storing Orders in an e-commerce application. Notice the primary key (outlined in blue), on the far left side of the table. It consists of a partition key called "OrderId" (outlined in red). Each Order item in the table contains the "OrderId" property, and it will be unique for each item in the table.
The second type of primary key is a composite primary key. A composite primary key consists of two elements: a partition key and a sort key. The image below shows an example of a table with a composite primary key.

This table stores the same Orders as our previous table, but it also includes information about each Order's Customer. The primary key (outlined in blue) on the left side of the table now has two parts -- a partition key (outlined in red) of CustomerId and a sort key of OrderId. Like with the simple primary key, each item in this table will need to include the primary key (both elements), and it is the combination of these two elements that will uniquely identify each item in the table.
Notice how both primary key structures include a partition key element. This partition key is crucial to DynamoDB's infinite scaling capabilities.
Horizontal scaling and the partition key
As noted in the introduction, your DynamoDB table isn't running on a single supercomputer powered by qubits. Rather, it's distributed across an entire fleet of computers, where a single computer holds a subset of your table's data. These subsets are called 'partitions', and they enable essentially infinite scaling of your DynamoDB table.
Let's walk through this with an example.
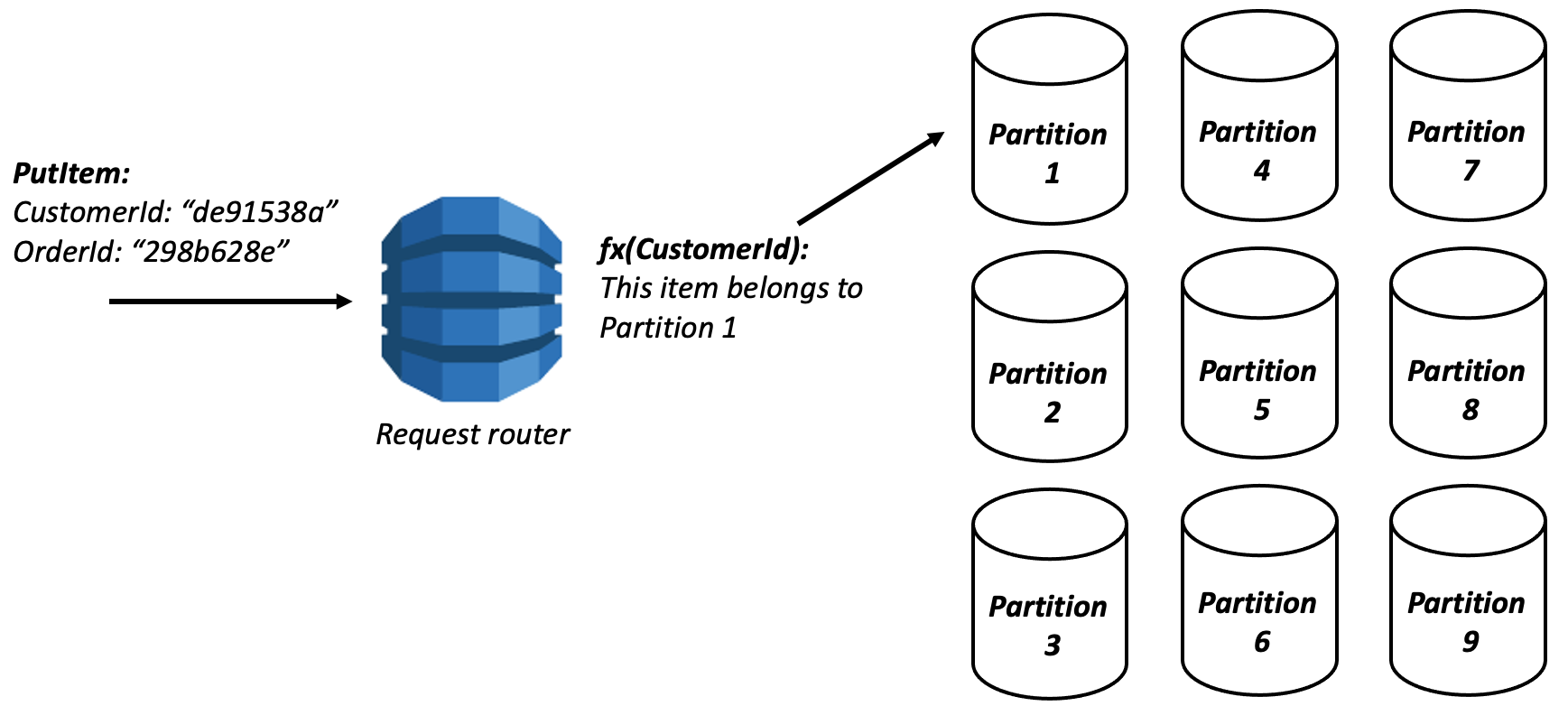
When you write an item to your DynamoDB table, the request will first be handled by a frontend service called the request router.

The request router doesn't store your actual data. Its job is to understand metadata about your table and its partitions, then route the request to the right partition.
This request router will parse the partition key from your item and hash it.* Then, based on the hashed value of the partition key, it will determine the partition to which this item should be written.
* Why does DynamoDB hash the partition key before placing it on a partition? This is to better spread data across your partitions. Imagine you had a sequential identifer as your partition key, and you wanted to iterate over sequential identifiers for one of your access patterns. If these values weren't hashed before locating on a partition, you could end up with hot partitions for these access patterns. A similar principle exists for MongoDB and is explained here.

In the image above, the request router determined that the incoming item belonged to Partition 1 and send the request there to be handled.
Reading items from DynamoDB follows the same flow. The request router will parse the partition key, then route the read request to the proper partition to read and return the data.

Each partition is roughly 10GB in size, so DynamoDB will add additional partitions to your table as it grows. A small table may only have 2-3 partitions, while a large table could have thousands of partitions.
The great part about this setup is how well it scales. The request router's work of finding the proper node has time complexity of O(1).

This is the crucial fact about DynamoDB's horizontal scaling -- even with thousands of partitions, the request router's job is a fast, consistent operation that narrows your table from multiple terabytes down to a more manageable 10GB.
How partitions do (and don't) matter in DynamoDB
Now that we know how partitions work in DynamoDB, let's see how they do and don't matter for you as a DynamoDB user.
We'll start with how they don't matter. On a practical basis, you don't need to know about individual partitions in your DynamoDB table. You won't need to specify the partition to use when reading or writing an item into DynamoDB. The request router handles all of this for you.
Not only that, but you can't know about individual partitions in DynamoDB. All requests go through the request router and use an (undisclosed) hash function before placing items, so you couldn't understand the various partitions even if you wanted to. Note that this is different than other NoSQL databases, such as Cassandra, where clients can be topology-aware and thus go directly to a specific partition rather that hitting a shared router first.
There is a slight performance hit of using a shared request router, as client requests will now take an additional network hop to fulfill the request. However, your client's ignorance about partitions makes it easier for you to reason about as a DynamoDB user.
First, your client doesn't need to request and maintain cluster metadata when interacting with the DynamoDB backend. This reduces the initial information your client needs to pull down when connecting as well as the continued chatter to keep aware of cluster updates.
Additionally, it makes it easier for DynamoDB to provide strong performance guarantees around your data. A few years ago, the partition performance story was more nuanced. For high-scale tables, you needed to be aware of your partitions and the request distribution across partitions. Your provisioned throughput was spread equally across all partitions in your table, so you would need to provision capacity for your highest-traffic partition.
In 2018, DynamoDB announced adaptive capacity for your partitions. With adaptive capacity, your provisioned throughput is shifted around to the partitions that need it rather than equally across all partitions. DynamoDB will take the requisite actions to ensure your capacity is used efficiently. It can transparently add new partitions as your data size grows, or it can split highly-used partitions into sub-partitions to ensure it can provide consistent performance.
With these improvements, you can think less about DynamoDB partitions. As long as you are fitting within the partition throughput limit, you don't need to worry about balancing your partitions.
While you don't need to know the details about partitions on a practical matter, understanding DynamoDB partitions helps on a theoretical matter. By understanding how DynamoDB uses partitions and why it matters, it helps to build your mental model of how DynamoDB works. After all, the principles of single-table design seem pretty wild if you're coming from a normalized, relational database model.
Once you understand the centrality of partitions in DynamoDB, the rest of DynamoDB's data modeling makes sense.
How partitions affect data modeling in DynamoDB
Let's close this out by discussing a few implications of DynamoDB partitions.
Primacy of primary keys
The most important implication of DynamoDB's partition is the primacy of primary keys. We've seen how the request router immediately uses the partition key to route a request to the proper partition. Because of this, DynamoDB pushes hard for you to include the partition key in your requests.
The DynamoDB API has three main types of actions:
- Single-item requests (
PutItem,GetItem,UpdateItem, andDeleteItem) that act on a single, specific item and require the full primary key; Query, which can read a range of items and must include the partition key;Scan, which can read a range of items but searches across your entire table.
Other than the wildly-inefficient (for most use cases!) Scan operation, you must include the partition key in any request to DynamoDB.
In the background section, we noted that DynamoDB is schemaless outside the primary key. Both of these characterisitcs -- general schemalessness, with an exception for the primary key -- are due to DynamoDB's partitioning scheme.
DynamoDB forces your access of items to be centered on the primary key. Thus, it needs to enforce that the primary key exists for each item so that it can be indexed appropriately.
For the rest of the item, however, the shape is irrelevant. You won't have foreign key references to other tables, like you would in a relational database. Nor will you have neatly structured result sets with typed columns. Because the primary key is the only thing that matters, the rest of the data is just coming along for the ride.
DynamoDB is more like a key-value store than a spreadsheet. The key might be simple, with just a partition key, or complex, with a partition key plus a sort key, but the value is still just a blob.
One word of caution -- DynamoDB's schemaless nature does not mean your data shouldn't have a schema somewhere. You need to maintain and validate your data schemas within your application code rather than relying on your database to handle it.
Note that while other NoSQL databases use the same partitioning concept to enable horizontal scaling, not all of them restrict the API accordingly. If you're not careful, you can lose the benefits of horizontal scaling by using scatter-gather queries to each of your partitions!
When thinking about data access in DynamoDB, remember this image:

You can query efficiently by the attributes in your primary key, but you cannot query efficiently by other attributes in your table. Design your table accordingly!
Consider how to split up your data
The second implication of DynamoDB's partition is that it forces you to consider how to split up your data.
One of the biggest mistakes I see new DynamoDB users make is to put a lot of unrelated items into a single item collection. Don't do that! Rather, use a high-cardinality value for your partition key.
If you have users in your application, the userId is often a good partition key. This will ensure different users are placed in different item collections, and you can have lots of users using your application without affecting each other.
On the other hand, using something like a boolean value (true / false) or an enum (red / green / blue) as your partition key is not a good idea. You don't have high enough cardinality to really distribute your data across your partitions.
Careful consideration of how you split up your data can also assist with complex access patterns.
You'll often hear that DynamoDB can't handle full-text search or complex filtering patterns. And it's true -- if you want to perform full-text search across your entire application, you'll probably want to reach for dedicated search infrastructure.
However, your search needs often aren't that extensive. You can usually narrow your search requirements to a smaller section of your dataset. For example, you may want to allow full-text search on users within an organization. If that's the case, DynamoDB can work well. You can partition your users by organization. When a client makes a search request, you can pull in all the users for that organization then perform an in-memory search on the results before sending back to the client. If the corpus you're searching against is narrow (here, the set of users in an organization), you may not need dedicated search infrastructure.
In a recent chat with Rick Houlihan, Rick told me that this is how Amazon.com retail handles most of their e-commerce search and filtering. If you search for "sony 42 inch tv", the backend doesn't search the entire inventory of Amazon.com. Rather, it narrows down to the TV category, then performs a more targeted search there.
You can use this same strategy with geo-lookups. If you want to provide geo-search on your dataset, figure out how you can break it down -- into countries, states, cities, geohashes, etc. Narrow your initial search space when reading from DynamoDB, then provide an in-memory filter to further reduce your options.
By understanding the role that partitions play, you can lean into the efficiency of DynamoDB by segmenting your data accordingly.
No joins + denormalization
Last but not least, DynamoDB's lack of support for joins is mostly due to the partitioning scheme.
When a relational database is performing a join operation, it's evaluating portions of two separate tables for comparison and combination. This poses two problems for DynamoDB.
First, the relevant portions of the two tables may be on two separate partitions. This adds additional network hops to perform the separate reads, as well as a combination step on a centralized node before returning to the client.
Second, it's possible that a client will want to join an attributes that aren't part of the primary key (and thus aren't indexed properly). This goes against DynamoDB's core philosophy around primary keys discussed above. Additionally, relational databases often include sophisticated query planners that determine the most efficient way to execute a given query. They include information about table structures and indices, as well as statistics on the contents of a particular table.
None of this is completely insurmountable in a partitioned database like DynamoDB. MongoDB offers the $lookup aggregation, which performs an outer join. Additionally, partitioned relational database options like Vitess offer support for joins. However, it adds complexity -- complexity for the DynamoDB backend and complexity for the DynamoDB user. Further, it adds performance variability, which is the bane of DynamoDB.
Instead, DynamoDB forces you to model around the lack of joins. This might mean denormalization or it could mean pre-joining heterogenous items into the same partition. You can choose the proper approach based on your needs. Whichever route you choose, you won't be guessing about the performance implications as your application grows.
Conclusion
In this post, we learned about DynamoDB partitions -- what they are, how they do (and don't) matter, and how they should affect your data modeling.
The main takeaway from this post is that you can and should learn the philosophy of DynamoDB. It's not that big of a surface area, particularly when compared to all the knobs and buttons with a relational database. By learning a few key principles, you'll build a proper mental model of DynamoDB, and it will be easier to use it correctly.
If you have questions or comments on this piece, feel free to leave a note below or email me directly.